An introduction to sampling methods
Содержание:
- Quadrature Sampling¶
- Different Types of Sampling Techniques
- Sampling Distribution — Importance
- What is Sampling?
- Мотивация
- Какие инструменты использовать?
- Probability sampling methods
- Методика
- What Is Sampling?
- Receiver Side¶
- Client Sampling Configuration
- Steps involved in Sampling
- Sampling Distribution — Central Limit Theorem
- Population vs sample
- Основные этапы построения выборки
- Sampling thresholds
- Мнения
- Types of Audit Sampling
Quadrature Sampling¶
The term “quadrature” has many meanings, but in the context of DSP and SDR it refers to two waves that are 90 degrees out of phase. Why 90 degrees out of phase? Consider how two waves that are 180 degrees out of phase are essentially the same wave with one multiplied by -1. By being 90 degrees out of phase they become orthogonal, and there’s a lot of cool stuff you can do with orthogonal functions. For the sake of simplicity, we use sine and cosine as our two sine waves that are 90 degrees out of phase.
Next let’s assign variables to represent the amplitude of the sine and cosine. We will use for the cos() and for the sin():
We can see this visually by plotting I and Q equal to 1:
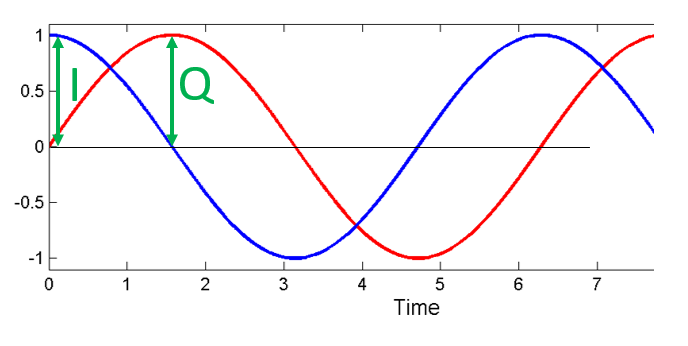
We call the cos() the “in phase” component, hence the name I, and the sin() is the 90 degrees out of phase or “quadrature” component, hence Q. Although if you accidentally mix it up and assign Q to the cos() and I to the sin(), it won’t make a difference for most situations.
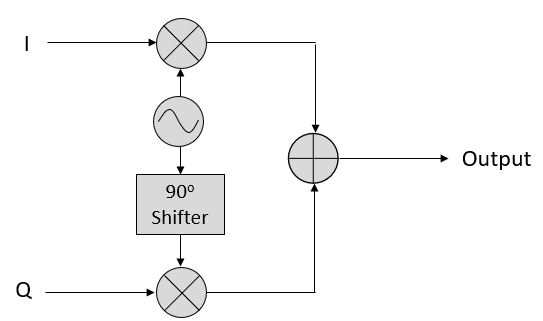
IQ sampling is more easily understood by using the transmitter’s point of view, i.e., considering the task of transmitting a RF signal through the air. What we do as the transmitter is add the sin() and cos(). Let’s say x(t) is our signal to transmit:
What happens when we add a sine and cosine? Or rather, what happens when we add two sinusoids that are 90 degrees out of phase? In the video below, there is a slider for adjusting I and another for adjusting Q. What is plotted are the cosine, sine, and then the sum of the two.

(The code used for this pyqtgraph-based Python app can be found here)
The important take-aways are that when we add the cos() and sin(), we get another pure sine wave with a different phase and amplitude. Also, the phase shifts as we slowly remove or add one of the two parts. The amplitude also changes. This is all a result of the trig identity: , which we will come back to in a bit. The “utility” of this behavior is that we can control the phase and amplitude of a resulting sine wave by adjusting the amplitudes I and Q (we don’t have to adjust the phase of the cosine or sine). For example, we could adjust I and Q in a way that keeps the amplitude constant and makes the phase whatever we want. As a transmitter this ability is extremely useful because we know that we need to transmit a sinusoidal signal in order for it to fly through the air as an electromagnetic wave. And it’s much easier to adjust two amplitudes and perform an addition operation compared to adjusting an amplitude and a phase. The result is that our transmitter will look something like this:
Different Types of Sampling Techniques
Here comes another diagrammatic illustration! This one talks about the different types of sampling techniques available to us: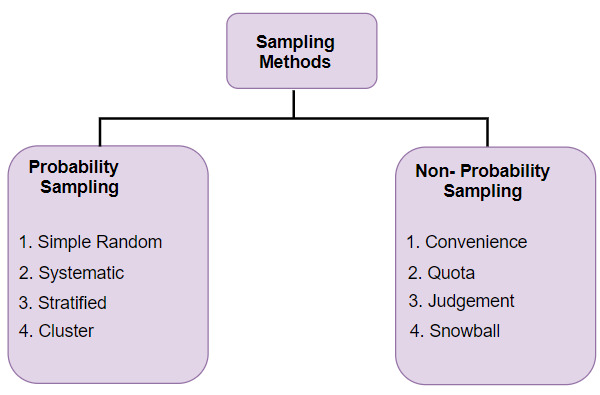
- Probability Sampling: In probability sampling, every element of the population has an equal chance of being selected. Probability sampling gives us the best chance to create a sample that is truly representative of the population
- Non-Probability Sampling: In non-probability sampling, all elements do not have an equal chance of being selected. Consequently, there is a significant risk of ending up with a non-representative sample which does not produce generalizable results
For example, let’s say our population consists of 20 individuals. Each individual is numbered from 1 to 20 and is represented by a specific color (red, blue, green, or yellow). Each person would have odds of 1 out of 20 of being chosen in probability sampling.
With non-probability sampling, these odds are not equal. A person might have a better chance of being chosen than others. So now that we have an idea of these two sampling types, let’s dive into each and understand the different types of sampling under each section.
Sampling Distribution — Importance
Sampling distributions tell us which outcomes are likely, given our research hypotheses. So perhaps our hypothesis is that a coin is balanced: both heads and tails have a 50% chance of landing up after a flip. This hypothesis implies the sampling distribution shown below for the number of heads resulting from 10 coin flips.
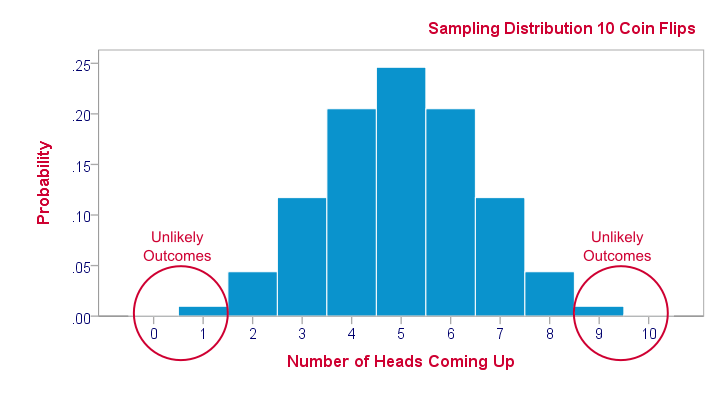
This tells us that from 1,000 such random samples of 10 coin flips, roughly 10 samples (1%) should result in 0 or 1 heads landing up. We therefore consider 0 or 1 heads an unlikely outcome. If such an outcome occurs anyway, then perhaps the coin wasn’t balanced after all. We reject our hypothesis of equal chances for heads and tails and conclude that heads has a lower than 50% chance of landing up.
What is Sampling?
Let’s start by formally defining what sampling is.
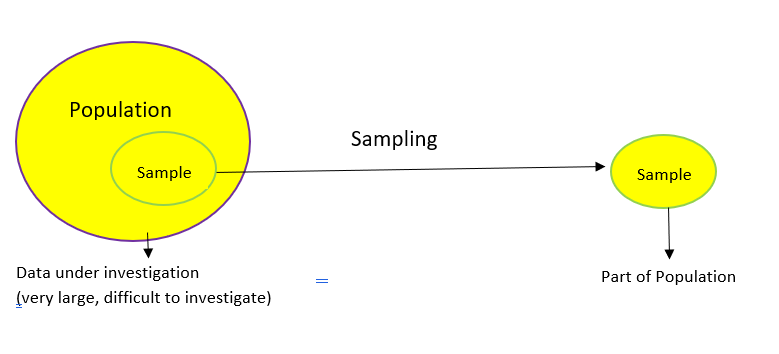
The above diagram perfectly illustrates what sampling is. Let’s understand this at a more intuitive level through an example.
We want to find the average height of all adult males in Delhi. The population of Delhi is around 3 crore and males would be roughly around 1.5 crores (these are general assumptions for this example so don’t take them at face value!). As you can imagine, it is nearly impossible to find the average height of all males in Delhi.
It’s also not possible to reach every male so we can’t really analyze the entire population. So what can we do instead? We can take multiple samples and calculate the average height of individuals in the selected samples.

But then we arrive at another question – how can we take a sample? Should we take a random sample? Or do we have to ask the experts?
Let’s say we go to a basketball court and take the average height of all the professional basketball players as our sample. This will not be considered a good sample because generally, a basketball player is taller than an average male and it will give us a bad estimate of the average male’s height.
Here’s a potential solution – find random people in random situations where our sample would not be skewed based on heights.
Мотивация
Сглаживание проявляется в случае 2D-изображений в виде муара и пиксельных краев, в просторечии известных как « неровности ». Общие обработки сигналов и обработка изображений знания предполагают , что для достижения идеального устранения наложения спектров , надлежащие пространственный отбора проб на Найквист скорости (или выше) после применения 2D сглаживающего фильтра не требуются. Поскольку этот подход потребовал бы прямого и обратного преобразования Фурье , были разработаны менее требовательные в вычислительном отношении приближения, такие как суперсэмплинг, чтобы избежать переключений областей, оставаясь в пространственной области («области изображения»).
Какие инструменты использовать?
Пожалуй, можно выделить три основные группы приемов, относящихся к категории «семплинг»:
Раздача бесплатных образцов продукции
Таким образом, можно познакомить покупателя с новым брендом, товаром, его свойствами и преимуществами. Согласно статистике покупатель склонен доверять проверенным компаниям и покупать уже протестированную на личном опыте продукцию. Но в том случае, когда предоставляет возможность лично убедиться в уникальных свойствах и качествах нового товара, причем это необязательно делать в торговой точке, а можно унести продукт домой, то интерес потребительской аудитории возрастает в несколько раз. Самый видимый эффект этот прием оказывает при первичном запуске товара на рынке или при повторной рекламной кампании, но с акцентом на измененные свойства товара. Раздача бесплатных образцов продукции довольно активно применяется участниками рынка, так как имеет видимый результат в качестве повышения уровня спроса на продвигаемый товар.
Раздача рекламных материалов с прикрепленным пробником продукции
Как правило, подобные акции проходят не только в местах продаж, но и на открытых пространствах (улицах, массовых мероприятиях, на территории торгово-развлекательных центров). Сама механика раздачи печатной продукции не так эффективна, как в тандеме с сэмплингом. Таким образом, у потенциального потребителя появляется возможность не только узнать полезную информацию о продукте, но и протестировать (попробовать) пробный экземпляр в действии. Например, это может быть реклама нового чая с помощью информационной листовки с прикрепленным к нему образцом продукции или продвижение обновленной линейки известного косметического бренда в виде буклета с сэмплом крема для лица.
Комплекс мероприятий
Если смотреть на сэмплинг как механику btl активности в широком спектре, то к проектам подобного рода можно отнести все мероприятия, в той или иной мере знакомящие покупателей товаров (дегустация, тест-драйв, спреинг и т.д). К примеру, производитель круп или макарон вполне может организовать дегустацию своей продукции в торговой точке, а в качестве дополнительного стимула для покупки товара вручать бесплатный образец продукции (на одну порцию).
Конечно, использование того или иного инструмента должно быть аргументировано, продумано и качественно организовано, только в этом случае можно говорить о положительном и эффективном результате. Однако в руках профессионалов сэмплинг как прием маркетинга может заиграть совсем новым красками, ведь никто не запрещает экспериментировать, совмещать сразу несколько техник в одном проекте. Главное, не забывать один из главных принципов маркетинга: «Не будьте занудой!»
Probability sampling methods
Probability sampling means that every member of the population has a chance of being selected. It is mainly used in quantitative research. If you want to produce results that are representative of the whole population, probability sampling techniques are the most valid choice.
There are four main types of probability sample.
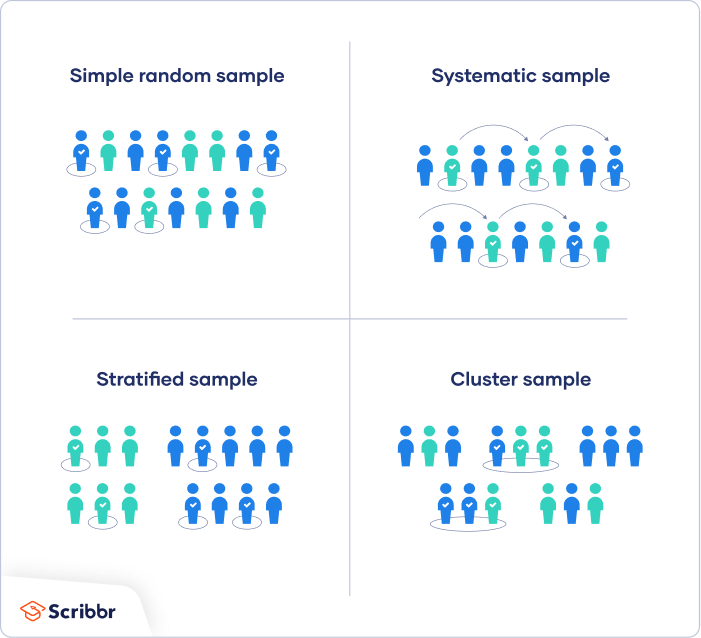
1. Simple random sampling
In a simple random sample, every member of the population has an equal chance of being selected. Your sampling frame should include the whole population.
To conduct this type of sampling, you can use tools like random number generators or other techniques that are based entirely on chance.
Example
You want to select a simple random sample of 100 employees of Company X. You assign a number to every employee in the company database from 1 to 1000, and use a random number generator to select 100 numbers.
2. Systematic sampling
Systematic sampling is similar to simple random sampling, but it is usually slightly easier to conduct. Every member of the population is listed with a number, but instead of randomly generating numbers, individuals are chosen at regular intervals.
Example
All employees of the company are listed in alphabetical order. From the first 10 numbers, you randomly select a starting point: number 6. From number 6 onwards, every 10th person on the list is selected (6, 16, 26, 36, and so on), and you end up with a sample of 100 people.
If you use this technique, it is important to make sure that there is no hidden pattern in the list that might skew the sample. For example, if the HR database groups employees by team, and team members are listed in order of seniority, there is a risk that your interval might skip over people in junior roles, resulting in a sample that is skewed towards senior employees.
3. Stratified sampling
Stratified sampling involves dividing the population into subpopulations that may differ in important ways. It allows you draw more precise conclusions by ensuring that every subgroup is properly represented in the sample.
To use this sampling method, you divide the population into subgroups (called strata) based on the relevant characteristic (e.g. gender, age range, income bracket, job role).
Based on the overall proportions of the population, you calculate how many people should be sampled from each subgroup. Then you use random or systematic sampling to select a sample from each subgroup.
Example
The company has 800 female employees and 200 male employees. You want to ensure that the sample reflects the gender balance of the company, so you sort the population into two strata based on gender. Then you use random sampling on each group, selecting 80 women and 20 men, which gives you a representative sample of 100 people.
4. Cluster sampling
Cluster sampling also involves dividing the population into subgroups, but each subgroup should have similar characteristics to the whole sample. Instead of sampling individuals from each subgroup, you randomly select entire subgroups.
If it is practically possible, you might include every individual from each sampled cluster. If the clusters themselves are large, you can also sample individuals from within each cluster using one of the techniques above. This is called multistage sampling.
This method is good for dealing with large and dispersed populations, but there is more risk of error in the sample, as there could be substantial differences between clusters. It’s difficult to guarantee that the sampled clusters are really representative of the whole population.
Example
The company has offices in 10 cities across the country (all with roughly the same number of employees in similar roles). You don’t have the capacity to travel to every office to collect your data, so you use random sampling to select 3 offices – these are your clusters.
Receive feedback on language, structure and layout
Professional editors proofread and edit your paper by focusing on:
- Academic style
- Vague sentences
- Grammar
- Style consistency
Методика
Вычислительная стоимость и адаптивная суперсэмплинг
Суперсэмплинг требует больших вычислительных ресурсов, поскольку требует гораздо большей памяти видеокарты и пропускной способности памяти , поскольку объем используемого буфера в несколько раз больше. Обойти эту проблему можно с помощью метода, известного как адаптивная суперсэмплинг , при котором суперсэмплинг подвергаются только пиксели на краях объектов.
Первоначально в каждом пикселе берутся только несколько образцов. Если эти значения очень похожи, только эти образцы используются для определения цвета. В противном случае используются другие. Результатом этого метода является то, что большее количество выборок рассчитывается только там, где это необходимо, что улучшает производительность.
Шаблоны суперсэмплинга
При отборе образцов в пределах пикселя положение образцов должно быть определено каким-то образом. Хотя количество способов, которыми это можно сделать, бесконечно, есть несколько обычно используемых способов.
Сетка
Самый простой алгоритм . Пиксель разбивается на несколько подпикселей, и образец берется из центра каждого. Это быстро и легко реализовать. Хотя, из-за регулярного характера выборки, наложение спектров все еще может происходить, если используется небольшое количество подпикселей.
Случайный
Также известный как стохастическая выборка, он позволяет избежать регулярной суперсэмплинга сетки. Однако из-за неравномерности рисунка в некоторых областях пикселя сэмплы оказываются ненужными, а в других — отсутствуют.
Диск Пуассона
Точечные выборки, созданные с использованием выборки диска Пуассона, и графическое представление минимального межточечного расстояния
Алгоритм выборки диска Пуассона размещает выборки случайным образом, но затем проверяет, что любые две не слишком близки. Конечным результатом является равномерное, но случайное распределение выборок. Однако вычислительное время, необходимое для этого алгоритма, слишком велико, чтобы оправдать его использование при рендеринге в реальном времени , если только сама выборка не требует больших вычислительных затрат по сравнению с позиционированием точек выборки или точки выборки не перемещаются для каждого отдельного пикселя.
Взволнованный
Модификация сеточного алгоритма для аппроксимации диска Пуассона. Пиксель разбивается на несколько подпикселей, но выборка берется не из центра каждого, а из случайной точки внутри подпикселя. Конгрегация все еще может происходить, но в меньшей степени.
Повернутая сетка
Используется сетка 2 × 2, но образец образца поворачивается, чтобы избежать выравнивания образцов по горизонтальной или вертикальной оси, что значительно улучшает качество сглаживания для наиболее часто встречающихся случаев. Для оптимального шаблона угол поворота арктангенциальный ( 1 2 ) (около 26,6 °), а квадрат растягивается в раз √ 5 2 .
What Is Sampling?
Sampling is a process used in statistical analysis in which a predetermined number of observations are taken from a larger population. The methodology used to sample from a larger population depends on the type of analysis being performed, but it may include simple random sampling or systematic sampling.
Key Takeaways
- Certified Public Accountants use sampling during audits to determine the accuracy and completeness of account balances.
- Types of sampling include random sampling, block sampling, judgement sampling, and systematic sampling.
- Companies use sampling as a marketing tool to identify the needs and wants of their target market.
1:30
Receiver Side¶
Now let’s take the perspective of a radio receiver that is trying to receive a signal (e.g., an FM radio signal). Using IQ sampling, the diagram now looks like:
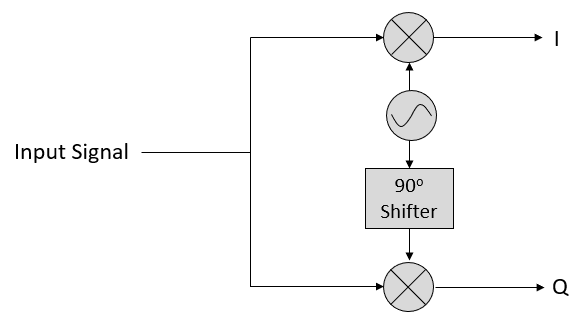
What comes in is a real signal received by our antenna, and those are transformed into IQ values. What we do is sample the I and Q branches individually, using two analog-to-digital converters (ADCs), and then we combine the pairs and store them as complex numbers. In other words, at each time step, you will sample one I value and one Q value and combine them in the form (i.e., one complex number per IQ sample). There will always be a “sample rate”, the rate at which sampling is performed. Someone might say, “I have an SDR running at 2 MHz sample rate.” What they mean is that the SDR receives two million IQ samples per second.
If someone gives you a bunch of IQ samples, it will look like a 1D array/vector of complex numbers. This point, complex or not, is what this entire chapter has been building to, and we finally made it.
Throughout this textbook you will become very familiar with how IQ samples work, how to receive and transmit them with an SDR, how to process them in Python, and how to save them to a file for later analysis.
Client Sampling Configuration
When using configuration object to instantiate the tracer, the type of sampling can be selected via and properties. Jaeger libraries support the following samplers:
- Constant () sampler always makes the same decision for all traces. It either samples all traces () or none of them ().
- Probabilistic () sampler makes a random sampling decision with the probability of sampling equal to the value of property. For example, with approximately 1 in 10 traces will be sampled.
- Rate Limiting () sampler uses a leaky bucket rate limiter to ensure that traces are sampled with a certain constant rate. For example, when it will sample requests with the rate of 2 traces per second.
- Remote (, which is also the default) sampler consults Jaeger agent for the appropriate sampling strategy to use in the current service. This allows controlling the sampling strategies in the services from a in Jaeger backend, or even dynamically (see Adaptive Sampling).
Adaptive Sampler
Adaptive sampler is a composite sampler that combines two functions:
- It makes sampling decisions on a per-operation basis, i.e. based on span operation name. This is especially useful in the API services whose endpoints may have very different traffic volumes and using a single probabilistic sampler for the whole service might starve (never sample) some of the low QPS endpoints.
- It supports a minimum guaranteed rate of sampling, such as always allowing up to N traces per seconds and then sampling anything above that with a certain probability (everything is per-operation, not per-service).
Per-operation parameters can be configured statically or pulled periodically from Jaeger backend with the help of Remote sampler. Adaptive sampler is designed to work with the upcoming Adaptive Sampling feature of the Jaeger backend.
Steps involved in Sampling
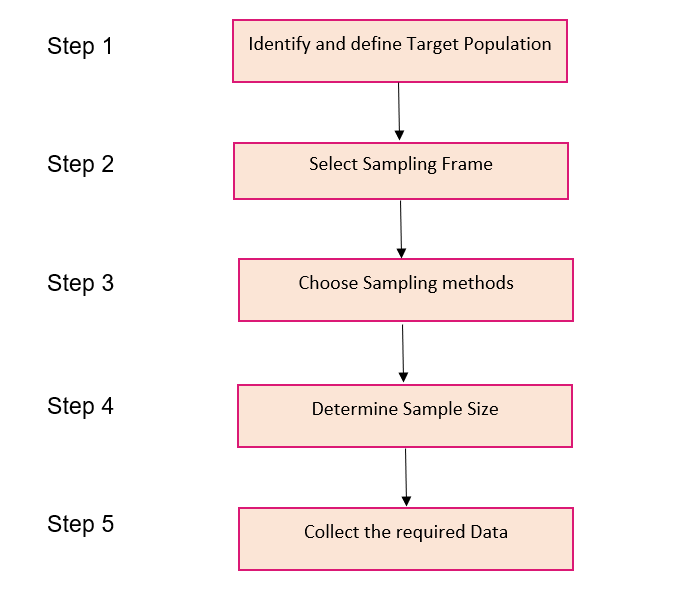
I firmly believe visualizing a concept is a great way to ingrain it in your mind. So here’s a step-by-step process of how sampling is typically done, in flowchart form!
Let’s take an interesting case study and apply these steps to perform sampling. We recently conducted General Elections in India a few months back. You must have seen the public opinion polls every news channel was running at the time:

Were these results concluded by considering the views of all 900 million voters of the country or a fraction of these voters? Let us see how it was done.
Step 1
So, to carry out opinion polls, polling agencies consider only the people who are above 18 years of age and are eligible to vote in the population.
Step 2
Sampling Frame – It is a list of items or people forming a population from which the sample is taken.
So, the sampling frame would be the list of all the people whose names appear on the voter list of a constituency.
Step 3
Generally, probability sampling methods are used because every vote has equal value and any person can be included in the sample irrespective of his caste, community, or religion. Different samples are taken from different regions all over the country.
Step 4
Sample Size – It is the number of individuals or items to be taken in a sample that would be enough to make inferences about the population with the desired level of accuracy and precision.
Larger the sample size, more accurate our inference about the population would be.
For the polls, agencies try to get as many people as possible of diverse backgrounds to be included in the sample as it would help in predicting the number of seats a political party can win.
Step 5
Once the target population, sampling frame, sampling technique, and sample size have been established, the next step is to collect data from the sample.
In opinion polls, agencies generally put questions to the people, like which political party are they going to vote for or has the previous party done any work, etc.
Based on the answers, agencies try to interpret who the people of a constituency are going to vote for and approximately how many seats is a political party going to win. Pretty exciting work, right?!
Sampling Distribution — Central Limit Theorem
The outcome of our simulation shows a very interesting phenomenon: the sampling distribution of sample means is very different from the of marriages over 976 inhabitants: the sampling distribution is much less skewed (or more symmetrical) and smoother.
In fact, means and sums are always (approximately) for reasonable sample sizes, say n > 30. This doesn’t depend on whatever population distribution the data values may or may not follow. This phenomenon is known as the central limit theorem.
Note that even for 1,000 samples of n = 10, our sampling distribution of means is already looking somewhat similar to the normal distribution shown below.
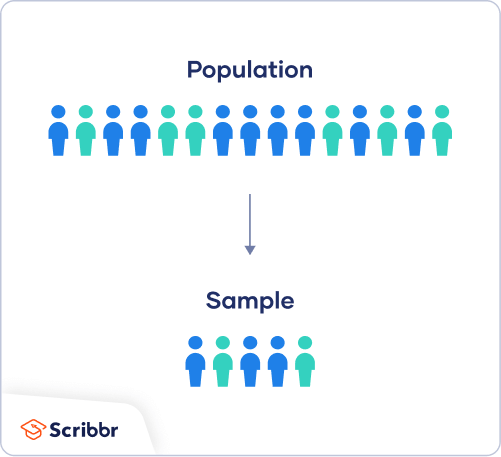
Population vs sample
First, you need to understand the difference between a population and a sample, and identify the target population of your research.
- The population is the entire group that you want to draw conclusions about.
- The sample is the specific group of individuals that you will collect data from.
The population can be defined in terms of geographical location, age, income, and many other characteristics.
It is important to carefully define your target population according to the purpose and practicalities of your project.
If the population is very large, demographically mixed, and geographically dispersed, it might be difficult to gain access to a representative sample.
Sampling frame
The sampling frame is the actual list of individuals that the sample will be drawn from. Ideally, it should include the entire target population (and nobody who is not part of that population).
Example
You are doing research on working conditions at Company X. Your population is all 1000 employees of the company. Your sampling frame is the company’s HR database which lists the names and contact details of every employee.
Sample size
The number of individuals you should include in your sample depends on various factors, including the size and variability of the population and your research design. There are different sample size calculators and formulas depending on what you want to achieve with statistical analysis.
Основные этапы построения выборки
Какой-либо универсальной, подходящей для всех задач анализа, последовательности действий при реализации процесса сэмплинга, вообще говоря, указать нельзя. Но наиболее типичной является следующая последовательность шагов.
Определение генеральной совокупности. На данном этапе аналитик должен определить из каких объектов будет состоять совокупность (людей, домохозяйств, предприятий, товаров и т.д.), какими признаками они характеризуются, а также произвести географическую и временную привязку. В некоторых случаях может возникнуть ситуация, когда совокупность может содержать наблюдения, которые будут являться следствием наблюдением другой совокупности (суперсовокупности). При этом совокупность и суперсовокупность могут частично перекрываться.
Определение основы выборки (sampling frame). В простейшем случае, в выборку может быть включен любой элемент совокупности — это называется прямым отбором. Однако на практике может оказаться полезным сформировать так называемую основу выборки — часть генеральной совокупности, элементы которой удовлетворяют требованиям решаемой задачи. Например, это могут быть люди старше 18 лет, клиенты с доходом выше среднего по региону и т.д. Возможно требование, чтобы каждый элемент совокупности попадал в основу выборки только один раз. Применяется показатель инцидентности (охвата) выборки, равный процентной доле генеральной совокупности, которая будет использоваться для отбора.
Выбор метода и алгоритма сэмплинга (план выборки). Этот выбор не всегда очевиден и однозначен. На практике приходится использовать опыт решения аналогичных задач, либо выбирать лучший метод экспериментально. Кроме этого выбранный метод зависит от типа данных и количества объектов.
Определение объёма выборки. Зависит от многих факторов. Например, в статистических методах исследования объём выборки должен обеспечивать возможность оценки законов распределения данных и их параметров. В машинном обучении объём обучающей выборки должен обеспечивать её полноту и репрезентативность, а также может зависеть от особенностей модели. Например, число примеров обучающей выборки для обучения нейронной сети должно превышать число межнейронных связей, которые настраиваются в процессе обучения. В противном случает сеть не приобретёт обобщающей способности.
Реализация процесса сэмплинга. Также имеет свои особенности. Например отбор наблюдений может производится из локальных или удалённых источников. Во втором случае процесс извлечения выборок больших объёмов может сопровождаться повышением нагрузки на сеть компании. Поэтому его лучше реализовывать в соответствии с наиболее безопасным временным регламентом
Кроме этого в процессе сэмплинга может произойти разрыв соединения, поэтому важно, чтобы после его восстановления процесс можно было продолжить, а не начинать сначала.
Сбор данных по отобранным объектам (если это необходимо). В некоторых случаях в процессе сэмплинга отбираются только идентификаторы объектов
Например, клиенты для опроса могут сначала отбираться по номерам клиентских карт, а потом в ходе опроса определяются их пол, возраст, доход и т.д.
Sampling thresholds
Default reports are not subject to sampling.
Ad-hoc queries of your data are subject to the following general thresholds for sampling:
- Analytics Standard: 500k sessions at the property level for the date range you are using
- Analytics 360: 100M sessions at the view level for the date range you are using
-
Queries may include events, custom variables, and custom dimensions and metrics. All other queries have a threshold of 1M
-
Historical data is limited to up to 14 months (on a rolling basis)
-
In some circumstances, you may see fewer sessions sampled. This can result from the complexity of your Analytics implementation, the use of view filters, query complexity for segmentation, or some combination of those factors. Although we make a best effort to sample up to the thresholds described above, it’s normal to sometimes see slightly fewer sessions returned for an ad-hoc query.
Мнения
Заместитель генерального директора ОАО «КапиталЪ Страхование» Дмитрий Боткин:
Сэмплинг страховых услуг может эффективно работать на больших массивах страхователей. Предложение бесплатных, «на пробу» страховых услуг в торговых центрах не окупает вложенных затрат: не та целевая аудитория. Сегодня страховщики собрали большие базы данных только по ОСАГО, и это опять-таки не та целевая аудитория. По этим базам число обратившихся в страховую компанию по рассылке методом директ-маркетинга не превысит 1%, а купят страховой полис еще меньше. Сэмплинг может хорошо работать только на массивах потенциальных страхователей с откликом не ниже 10%, а это уже хорошо подготовленная к финансовым услугам аудитория, которая пока есть только у банков. Вопрос только в том, готовы ли банки поделиться своими клиентами со страховщиками.
Директор по маркетингу группы «Альфа-Страхование» Евгений Белобородов:
Одна из основных причин, по которым сэмплинг не может быть в полной мере применен к страхованию, сводится к стоимости страхового продукта и циклу его потребления. Цикл потребления пищевых продуктов обычно составляет несколько дней. Распробовав йогурт или сок, человек очень быстро начинает совершать покупки за свой счет. В страховании же стандартный цикл потребления равен одному году. Стоимость упаковки йогурта, стакана сока, даже недельного пропуска в тренажерный зал или открытого тест-драйва просто несравнима с возможными затратами страховщика на восстановление автомобиля клиента после серьезной аварии и оплату лечения водителя при полученных травмах. Разбрасываться такими дорогими подарками страховым компаниям невыгодно.
Недельный же полис страхования не дает клиенту представления о страховом продукте — для этого надо, как минимум, успеть получить страховое возмещение, а вероятность наступления страхового события в недельный срок крайне мала: почувствовать «вкус» продукта практически невозможно.
Генеральный директор «Русской страховой компании» Геннадий Смирнов:
Недостаточное развитие сэмплинга в страховании, то есть бесплатных полисов, может быть связано с особенностями ведения бухгалтерского учета и налогообложения страховых компаний. Страховщику в случае выдачи бесплатного страхового полиса придется формировать страховые резервы за свой счет, из прибыли, что сильно повышает цену сэмплинг-акции. Правда, есть еще один способ, но он не приветствуется. Это оформить бесплатные полисы как платные за счет «серых» средств.
Генеральный директор СК «МРСС» Семен Акерман:
Подарки, которые дарит страховая компания, должны быть со смыслом и отражать сущность страхования. Тогда такая акция будет максимально стремиться к сэмплингу. Очень удачный пример встретился мне в Германии. Одна из страховых компаний делала подарок в виде молотка для разбивки лобового стекла при ДТП. Слоган у этой компании звучал примерно так: «В трудной ситуации мы думаем о вас». Понятно, что и молоток, и страхование имели своей целью «протянуть страхователю руку помощи в трудной ситуации».
Но в этом деле главное — не перегнуть палку. А то будем дарить бейсбольные биты с надписью «Всем врагам BMW посвящается».
Д.Брызгалов
Независимый эксперт
Types of Audit Sampling
Random Sampling
With random sampling, every item within a population has an equal probability of being chosen. It is the furthest removed from any potential bias because there is no human judgement involved in selecting the sample. For example, a random sample may include choosing the names of 25 employees out of a hat in a company of 250 employees. The population is all 250 employees, and the sample is random because each employee has an equal chance of being chosen.
Judgement Sampling
Auditor judgement may be used to select the sample from the full population. An auditor may only be concerned about transactions of a material nature. For example, assume the auditor sets the threshold for materiality for accounts payable transactions at $10,000. If the client provides a complete list of 15 transactions over $10,000, the auditor may just choose to review all transactions due to the small population size.
Alternatively, an auditor may identify all general ledger accounts with a variance greater than 10% from the prior period. In this case, the auditor is limiting the population from which the sample selection is being derived. Unfortunately, human judgement used in sampling always comes with the potential for bias, whether explicit or implicit.
Block Sampling
Block sampling takes a consecutive series of items within the population to use as the sample. For example, a list of all sales transactions in an accounting period could be sorted in various ways, including by date or by dollar amount. An auditor may request that the company’s accountant provide the list in one format or the other in order to select a sample from a specific segment of the list. This method requires very little modification on the auditor’s part, but it is likely that a block of transactions will not be representative of the full population.
Systematic Sampling
Systematic sampling begins at a random starting point within the population and uses a fixed, periodic interval to select items for a sample. The sampling interval is calculated as the population size divided by the sample size. Despite the sample population being selected in advance, systematic sampling is still considered random if the periodic interval is determined beforehand and the starting point is random.
Assume that an auditor is reviewing the internal controls related to a company’s cash account and wants to test the company policy that stipulates that checks exceeding $10,000 must be signed by two people. The population consists of every company check exceeding $10,000 during the fiscal year, which, in this example, was 300. The auditor uses probability statistics and determines that the sample size should be 20% of the population or 60 checks. The sampling interval is 5 (300 checks / 60 sample checks).
Therefore, the auditor selects every fifth check for testing. Assuming no errors are found in the sampling test work, the statistical analysis gives the auditor a 95% confidence rate that the check procedure was performed correctly. The auditor tests the sample of 60 checks and finds no errors, so he concludes that the internal control over cash is working properly.